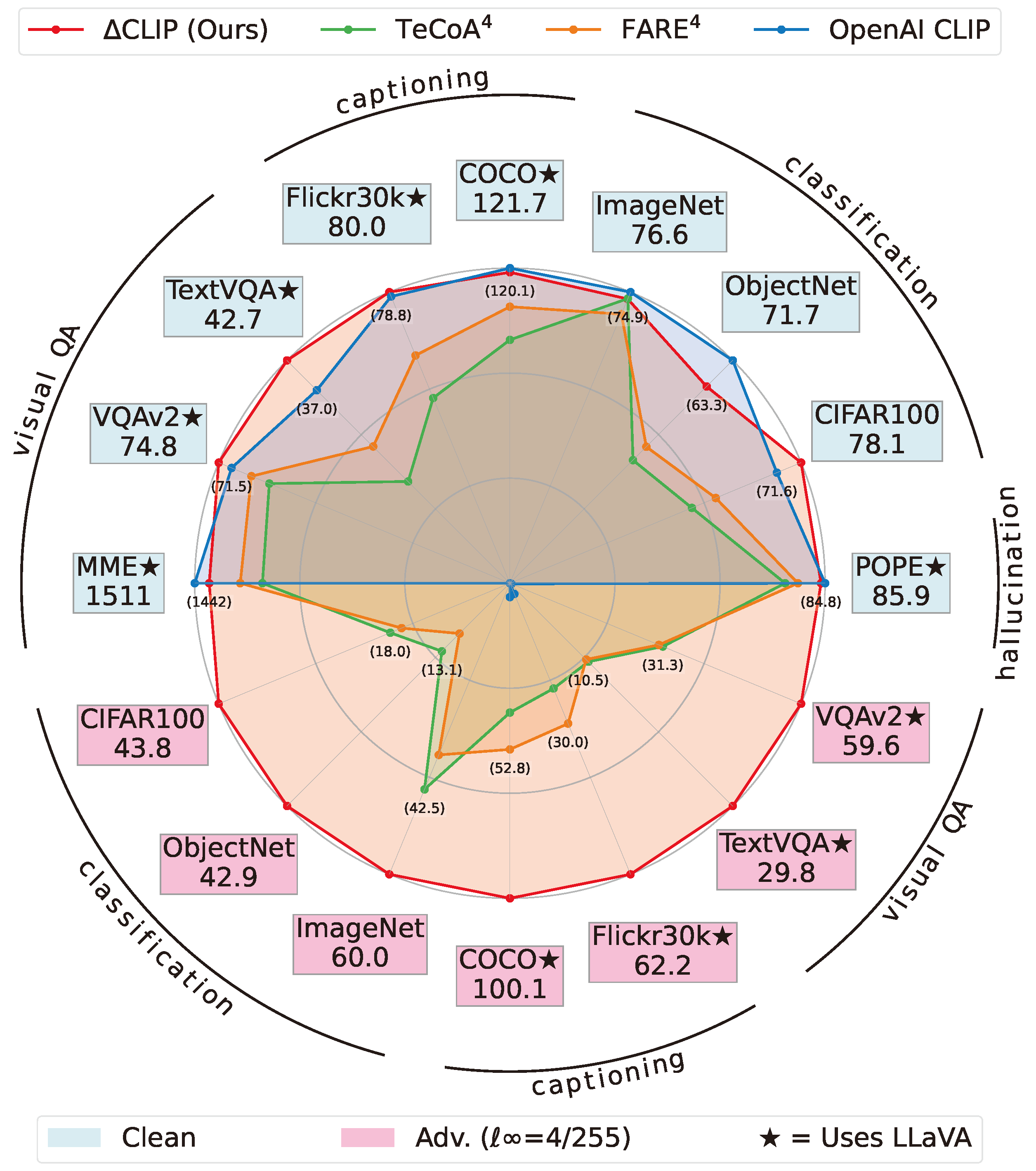
This paper investigates the robustness of vision-language models against adversarial visual perturbations and introduces a novel ``double visual defense" to enhance this robustness. Unlike previous approaches that resort to lightweight adversarial fine-tuning of a pre-trained CLIP model, we perform large-scale adversarial vision-language pre-training from scratch using web-scale data. We then strengthen the defense by incorporating adversarial visual instruction tuning. The resulting models from each stage, Delta-CLIP and Delta2-LLaVA, show substantially enhanced zero-shot robustness and set a new state-of-the-art in adversarial defense for vision-language models. For example, the adversarial robustness of Delta-CLIP surpasses that of the previous best models on ImageNet-1k by ~20%. Similarly, compared to prior art, Delta2-LLaVA brings a ~30\% robustness improvement to image captioning task and a ~20\% robustness improvement to visual question answering task. Furthermore, our models exhibit stronger zero-shot recognition capability, fewer hallucinations, and superior reasoning performance compared to baselines.
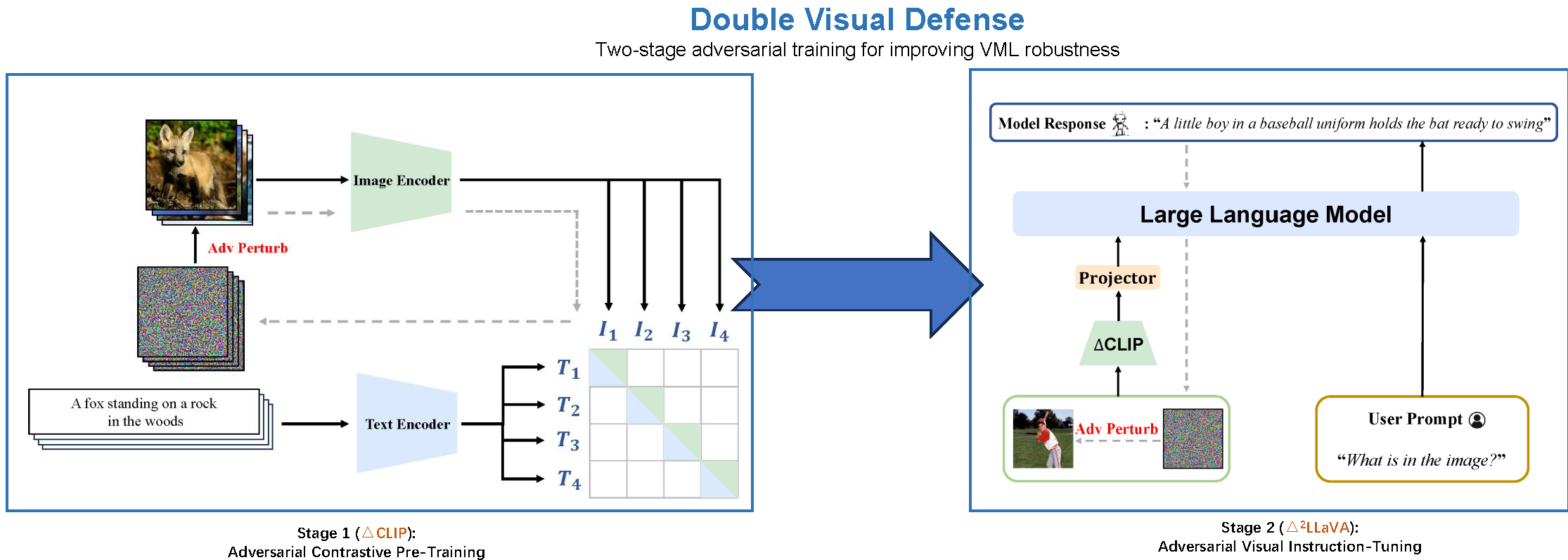
Our Double Visual Defense framework, which involves an adversarial contrastive pre-training stage and an adversarial visual instruction tuning stage.

Delta2-LLaVA shows less degree of hallucination compared to LLaVA that are based on previous robust CLIP models.

We observe an intriguing phenomenon that typographical attack naturally emerge from naive l-inf adversarial attacks when applied to our adversarially trained Delta2-LLaVA models.
@article{wang2025double,
title = {Double Visual Defense: Adversarial Pre-training and Instruction Tuning for Improving Vision-Language Model Robustness},
author = {Wang, Zeyu and Xie, Cihang and Bartoldson, Brian and Kailkhura, Bhavya},
journal = {arXiv preprint arXiv:2501.09446},
year = {2025}
}